정렬 유형
* 문자열에 많이 쓰이는 함수
reverse
begin과 end를 통해 전체를 바꿔도 되고 dopa.begin(), dopa.begin() + 3 이런식으로 부분만 바꿀 수 있음
substr
시작지점으로부터 몇개의 문자열을 뽑아냄
(시작지점, 몇개)
만약 시작지점만 넣게 되면 마지막까지 문자열을 뽑음
find
어떠한 문자열이 들어있나 찾음
만약 찾지 못한다면 문자열의 끝 위치인 string::npos를 반환
string dopa = "amumu is best";
int main(){
cout << dopa << "\n";
if(dopa.find("amumu") != string::npos){
cout << "dopa속에 아무무있다!\n";
}
cout << dopa.substr(0, 3) << "\n";
reverse(dopa.begin(), dopa.end());
cout << dopa << "\n";
return 0;
}
/*
amumu is best
dopa속에 아무무있다!
amu
tseb si umuma
*/
split
문법으로 지원 안해서 구현해야함
vector<string> split(string input, string delimiter) {
vector<string> ret;
long long pos = 0;
string token = "";
while ((pos = input.find(delimiter)) != string::npos) {
token = input.substr(0, pos); //분해할 기준이 되는 delimeter를 기준으로 input에서 그걸 찾음
ret.push_back(token); //ret에다 잘리기 전까지 넣고
input.erase(0, pos + delimiter.length()); //input을 지워가며 다시 찾기
}
ret.push_back(input);
return ret;
}
int main(){
string s = "안녕하세요 코딩 지니 입니다!";
string d = " ";
vector<string> a = split(s, d);
for(string b : a) cout << b << "\n";
/*
안녕하세요
코딩
지니
입니다!
*/
atoi(s.c_str())
문자열 -> int
입력 받은 글자가 문자열인지 숫자인지 확인해야 할 때
문자라면 0을 반환, 아니라면 숫자 반환
int main(){
string s = "1";
string s2 = "amumu";
cout << atoi(s.c_str()) << '\n';
cout << atoi(s2.c_str()) << '\n';
return 0;
}
/*
1
0
*/Basic
1. 단순 cmp 함수 사용
* cmp 리턴할때 오름차순은 < , 내림차순은 >
* cmp 함수 쓸 때 주의할 점
- vector를 넘길 때
const pair<int, int> &a, const pair<int, int> &b- vector<string> v를 넘길 때
vector<string> v;
bool cmp (string& a, string& b)
* string이랑 int 섞어 받을 때
구조체 만드는 아이디어
struct STU{
string name;
int kor, eng, math;
};
//정렬 함수에 사용할 함수
bool cmp(STU a, STU b) {
//국어도 같고 영어도 같고 수학도 같으면 이름 오름차순으로 정렬
if (a.kor == b.kor && a.eng == b.eng && a.math == b.math) return a.name < b.name;
//국어 같고 영어 같다면 수학 내림차순으로 정렬
if (a.kor == b.kor && a.eng == b.eng) return a.math > b.math;
//국어점수 같다면 영어 오름차순으로 정렬
if (a.kor == b.kor) return a.eng < b.eng;
//기본적으로 국어 내림차순으로 정렬
return a.kor > b.kor;
}[백준 1431] 시리얼 번호 (tistory.com)
tuple 쓰는 아이디어
[백준 10814] 나이순 정렬 (tistory.com)

* 문자, 숫자 아스키코드 변환
- 문자 -> 숫자 변환
1) isdigit(문자)으로 숫자 될 수 있는지 확인
2) ex. 문자= 5 일 때
아스키코드상 수로 표시된 문자열은 다음과 같음
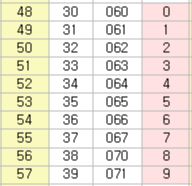
문자 5는 아스키코드 번호로 53임.
우리는 이걸 숫자 5로 바꿔주고 싶음
그럴 때
문자 - '0'(아스키코드로 48) 를 해주면
문자 5(아스키코드로 53) - '0'(아스키코드로 48) = 숫자 5

- 숫자로 된 문자에서 1을 더하면? 아스키코드에서 +1한 값
string s = "123";
s[0]++;
cout << s << "\n"; // 223
2. stable sort를 사용해야 할 때
- 원래의 순서를 손상시키지 않으면서 정렬해야 할 때
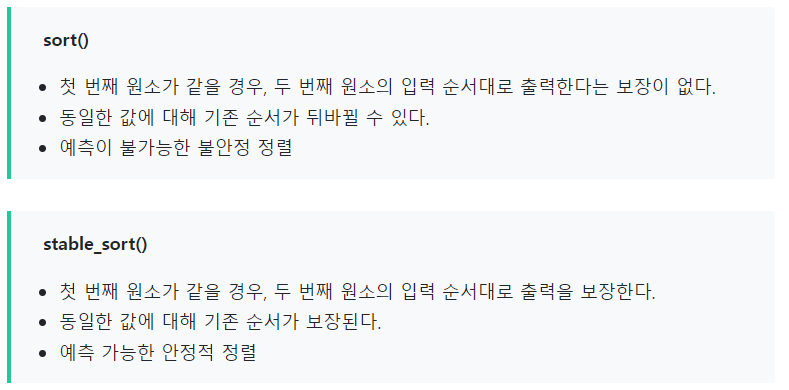
[백준 10814] 나이순 정렬 (tistory.com)
3. 문자열 자르기
substr()
문자열.substr(시작 위치, 길이)
- 첫 번째 인수에는 시작 위치를, 두 번째 인수에는 취득하고 싶은 문자수를 지정
- 문자열 시작은 0부터
#include <iostream>
using namespace std;
int main() {
string str1 = "abcde";
cout << str1.substr(0, 1) << endl; // a
cout << str1.substr(1, 1) << endl; // b
cout << str1.substr(2, 1) << endl; // c
cout << str1.substr(0, 2) << endl; // ab
cout << str1.substr(1, 2) << endl; // bc
return 0;
}
[백준 11656] 접미사 배열 (tistory.com)
4. 이분탐색 이용
upper_bound
- 용도 : 찾으려는 key 값을 초과하는 숫자가 배열 몇 번째에서 처음 등장하는지 찾기 위함
- ⭐ 사용 조건 : 탐색을 진행할 배열 혹은 벡터는 오름차순 정렬되어 있어야 함
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
vector<int> arr = { 1,2,3,4,5,6 };
cout << "upper_bound(3) : " << upper_bound(arr.begin(), arr.end(), 3) - arr.begin();
// 결과 -> upper_bound(3) : 3
return 0;
}
lower_bound
- 용도 : 찾으려는 key 값보다 같거나 큰 숫자가 배열 몇 번째에서 처음 등장하는지 찾기 위함
- ⭐ 사용 조건 : 탐색을 진행할 배열 혹은 벡터는 오름차순 정렬되어 있어야 함
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
int arr[6] = { 1,2,3,4,5,6 };
cout << "lower_bound(6) : " << lower_bound(arr, arr + 6, 6) - arr;
// 결과 -> lower_bound(6) : 5
return 0;
}[백준 7795] 먹을 것인가 먹힐 것인가 (tistory.com)
5. 중복제거
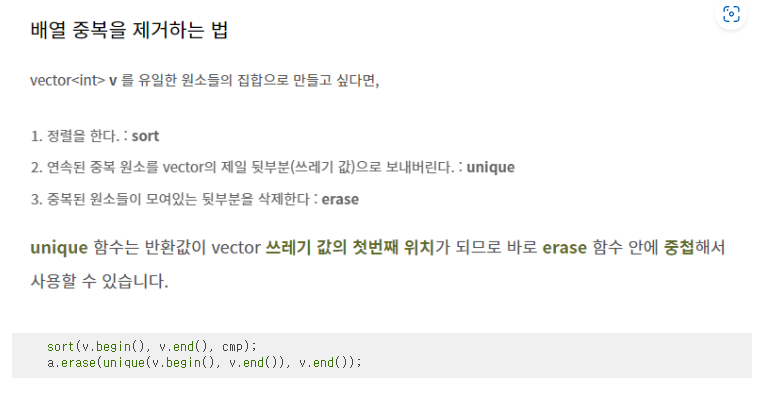
'Algorithm > 알고리즘 개념 정리' 카테고리의 다른 글
| [실전 알고리즘] 그리디 (0) | 2022.10.12 |
|---|---|
| [실전 알고리즘] 다이나믹 프로그래밍 (0) | 2022.10.10 |
| [알고리즘 오답노트] BFS (0) | 2022.10.05 |
| [실전 알고리즘] 정렬2(코테용) (0) | 2022.09.26 |
| [실전 알고리즘] 정렬1(면접용) (0) | 2022.09.20 |




댓글